High-volume recruiting strategies: the 6-fix operating model for scaling without compromise

High-volume hiring is not a different kind of recruiting. It is the same recruiting, with one difference: every weakness in the operating model compounds. A weak rubric becomes 200 inconsistent evaluations. An unstandardised question set becomes 600 candidates evaluated against different bars. An untracked feedback handoff becomes weeks of cycle-time creep. At 10 hires a quarter, you can patch around it. At 200, you cannot.
The fix is structural. The six pieces of structure that turn a recruiting function into one that can hold quality through volume are not optional polish; at this scale they are what stops the function from collapsing under its own throughput. Rubrics, structured questions, calibration, centralized feedback, automation, and AI-driven signal. Each one is doable on its own. Together they are an operating model.
This guide walks through what actually breaks first under volume, the six structural fixes that hold the line, what the product layer looks like when this is properly instrumented, and what teams running this play at real scale (200-300 candidates per role, 100+ hires per quarter) are actually seeing in their numbers.
What "high-volume" actually means
Most teams describe themselves as doing high-volume hiring at the moment volume is uncomfortable. That is a personal threshold, not an operational one. Operationally, the line is where the existing process stops scaling linearly with throughput: the moment a recruiter cannot personally review every inbound, the moment a hiring manager cannot personally meet every shortlisted candidate, the moment feedback cycle times start absorbing days instead of hours because there are simply too many calls.
Concretely, that tends to happen somewhere around 100+ hires per quarter (corporate roles) or 200+ applications per role (any role with broad addressable market). Below those numbers the function can run on goodwill, recruiter heroics, and lightweight process. Above them, the goodwill runs out and the process becomes the bottleneck. The 6 fixes below are designed for the operating side of that threshold.
Why traditional processes break at scale
Three things break first when volume hits. They tend to break in this order, and each one has a downstream effect that makes the next worse.
Evaluation consistency. Without explicit rubrics and structured questions, every interviewer ends up grading on a slightly different scale. At 10 candidates that is forgivable. At 300 it produces a pipeline of qualified people the team cannot compare to each other. Quality of hire takes the first hit; reviewability of the panel's own decisions takes the second.
Feedback cycle time. The volume of post-interview write-ups, follow-up emails, and debrief notes exceeds the capacity of the recruiter to chase. Hiring managers default to retroactive judgement ("I think they were strong, I forget specifically why"), and candidates start leaking to faster-moving competitors. Centralized capture is the only thing that closes this gap.
Recruiter time on the wrong work. Scheduling, note-formatting, scorecard chasing, and inbound triage swallow the day. The actual leverage activities (candidate relationships, hiring manager partnership, intake quality) get squeezed into the gaps. The function looks busy and produces less of what matters. Automation and AI signal are the only ways to claim that time back without expanding headcount.
When these three break together, the symptoms look like "we need more recruiters." Often the actual answer is that the operating model has not caught up with the volume.
- 12 panelists grading on 12 private rubrics
- Feedback lives in 47 Google Docs nobody can search
- Recruiter spends 60% of the day on scheduling and note-formatting
- AI applied on top scales the inconsistency
- One explicit rubric every panel uses, every loop
- Centralized capture against shared competencies, findable in seconds
- Automation absorbs the workflow tax; recruiter time goes back to candidates
- AI reads against the rubric the panel is also reading against
According to Metaview's 2026 AI & Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, the cost of running un-instrumented hiring at scale shows up most starkly in candidate loss: teams with good-or-below partnerships lose 8 in 10 qualified candidates to faster-moving competitors, versus 5 in 10 for teams with excellent ones. The four numbers below sit underneath the high-volume operating model.
Quality is the most important metric. We're constantly trying to figure out how to allow our recruiting team to be more hands-off the day-to-day process, to really dig into each individual candidate.”
The six structural fixes
The six structural fixes below are the operating-model upgrades that hold quality through scale. They are interlocking. Skipping any one of them compromises the rest: AI without rubrics scales the inconsistency, calibration without centralized feedback evaporates between sessions, automation without structured questions automates the wrong thing.
1. Standardize evaluation with rubrics
A rubric is the contract every interviewer signs on what "good" looks like for a competency. Without one, every panelist is operating on private criteria. With one, the panel's debates become substantive ("I scored them a 3 because their answer skipped the trade-off question, which I would expect at this level") instead of vibes-based. Rubrics are doable, undersold, and the single highest-leverage fix at scale.
2. Prepare structured interview questions
Structured questions are the rubric's operational expression. Instead of asking "tell me about a time you led a project," you ask the four specific questions you have decided will surface the four sub-competencies the rubric grades. Every candidate gets the same prompts. Evaluation becomes comparable across the pipeline. This is the difference between sampling a pipeline and reading it.
3. Train and calibrate interviewers
Calibration is the recurring check that interviewers are using the rubric the same way. Pull three recordings of the same competency across three panelists, watch them together, surface the implicit-criteria drift. Do this once a quarter and the rubric stays alive. Skip it and within six months you are back to private criteria, with extra steps.
4. Centralize feedback and reporting
Feedback that lives in 47 Google Docs, Slack threads, and recruiter heads is feedback that is not findable, not reviewable, and not analysable. The fix is one place where every scorecard, every panel note, and every hiring decision is captured against the same competency model. Two months in, you can ask which competencies your strongest hires consistently scored highest on. You cannot do that without centralization.
5. Automate repetitive tasks
Scheduling, calendar management, scorecard reminders, note formatting, debrief follow-ups. Each of these takes 5-10 minutes per touchpoint and there are dozens per role. At 200 roles a quarter you are looking at hundreds of recruiter hours absorbed by work that does not need a human. The automation does not have to be sophisticated. It just has to exist.
6. Use AI to go beyond automation
AI is the layer that turns operational capacity into operational signal. Application Review triages 200-300 inbound applications per role in minutes, against the same rubric the interview loop will use. AI Notes captures every interview verbatim and structures it against the scorecard. AI Filters lets the head of TA ask questions across hundreds of conversations ("which questions consistently distinguished the candidates we ended up hiring?") in seconds. The AI is not replacing the recruiter's judgement; it is replacing the recruiter's typing, so judgement scales with the pipeline.
The product layer that makes scale possible
The product layer is what makes the 6 fixes runnable at scale instead of aspirational. The cleanest way to see it is to walk through the actual surfaces a high-volume recruiter touches in a single day.
Application Review sits at the top of the funnel. Every inbound application gets checked against the role's rubric in seconds, with a structured explanation of why it is or is not a fit (not just a score). The recruiter still owns the cut. The agent just decides which 40 of the 200 inbounds the recruiter looks at, and surfaces fraud or AI-generated application flags before they hit the pipeline.
Notetaker sits at the interview layer. Every screen and panel call is captured verbatim, structured against the scorecard, and made searchable. The recruiter and panelists are not typing during the conversation, which means they are actually listening. The notes are consistent across the loop because they are auto-generated against the same competency model.
Reports sits at the operating layer. The leading indicators (scorecard completion rate, competency coverage per loop, panel-to-panel variance, feedback SLA adherence) live in one Friday-review surface. The head of TA can see at a glance which competencies are under-assessed, which panels are running hot or cold, which roles are slipping cycle-time targets.
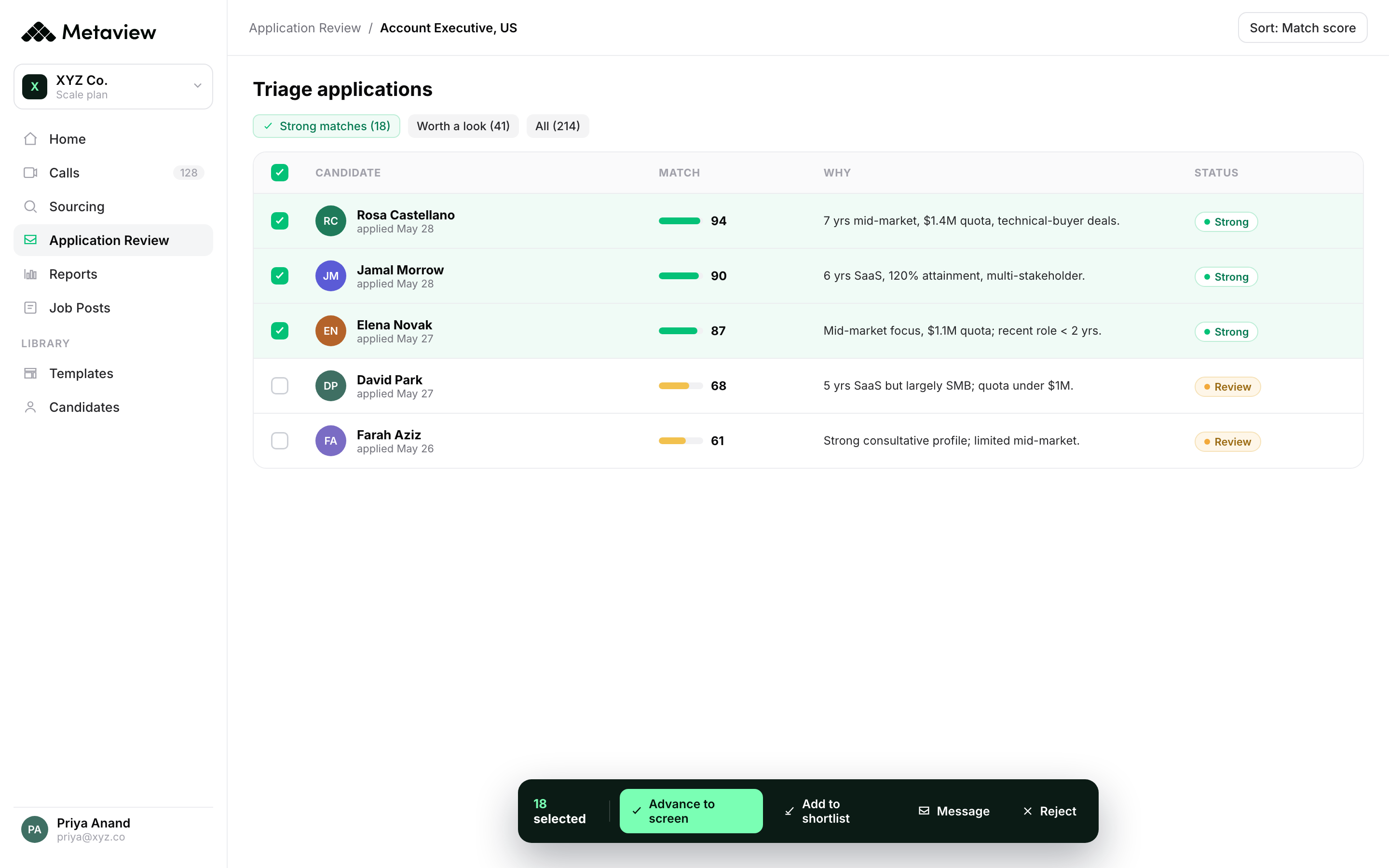
What customers running this play are operating
The customer pattern across teams running this play at real scale is consistent. Two short proof points below: the Cockroach Labs case study video, and the Workleap numbers from their inbound application overhaul.
What both customers describe is the same shift in what the function spends its time on. Less on the screening / note-taking / scorecard-chasing tier of work. More on the candidate-relationship / hiring-manager-partnership / intake-quality tier. The volume goes through the system; the recruiter goes back to the work that actually decides whether the hires are good.
We've actually saved about 70 working days for recruiters.”
Where to start
If your function is approaching the high-volume threshold and the operating model has not caught up yet, the order matters. Start with the rubric. Without it, automation scales inconsistency and AI surfaces noise. With it, every subsequent fix has something to bite against.
After the rubric: structured questions for every panel slot, then centralized capture so the panel's evaluations land in one place. Then automate the workflow tax (scheduling, follow-ups, scorecard reminders). AI Application Review and Notetaker are the last layer to add, because they are the most powerful when the rubric and the questions they read against are already correct.
The single hardest decision is when to commit to the structure. Most teams wait until volume has already started breaking the existing process, by which point the team is burned out and the pipeline is already leaky. The teams that scale well install the structure ahead of the volume curve and have it in production by the time the curve hits.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync, set up in under 10 minutes.
Frequently asked
What counts as high-volume recruiting?
Operationally, the threshold is wherever the existing process stops scaling linearly with throughput. As a rough rule, 100+ hires per quarter or 200+ applications per role both qualify. Below those numbers the function can run on recruiter heroics; above them, the operating model becomes the bottleneck.
Why do traditional processes break first at scale?
Three things break first: evaluation consistency (different interviewers using different implicit rubrics), feedback cycle time (post-interview write-ups exceeding recruiter capacity to chase), and recruiter time on low-leverage work (scheduling, note formatting, scorecard chasing). These three reinforce each other under volume, which is why fixing one without the others rarely sticks.
Can AI handle high-volume screening on its own?
It can do the first cut against an explicit rubric, but the recruiter still owns the decision. The AI's job is to triage 200 inbounds down to the 40 that warrant a recruiter's time, with a structured explanation of why each one was surfaced or set aside. Without the recruiter's judgement and the rubric the AI is checking against, the screen is just keyword matching at scale, which produces the same noise the recruiter was trying to escape.
How do you avoid the trap of automating before standardising?
Install the rubric and the structured questions before installing the automation. Automation that runs on top of inconsistent evaluation just produces inconsistent evaluation faster. The order is: rubric, then questions, then calibration, then centralized capture, then automation, then AI layer. It is the same order the 6 fixes are listed in for this exact reason.
What is the single most important fix to install first?
The rubric. Every other fix is downstream of having an explicit definition of what "good" looks like for each competency the role demands. Once that exists, structured questions become writable, calibration becomes possible to debate, centralized capture has something to be captured against, and the AI layer has something to read against. Without the rubric, the other five fixes either do not work or actively make things worse.
How long does it take to put this operating model in place?
Most of the work is decision-making, not implementation. The rubric for a role family takes a senior recruiter and a hiring manager a couple of focused hours. Structured questions take another hour per panel slot. Calibration is a recurring 30-60 minute session per quarter. Centralized capture and AI Application Review can both be live in under a week with modern tooling. The hardest part is committing to the structure; the rest is calendar coordination.



