Interview rubrics: How to standardize and supercharge your hiring process

Most teams write a careful rubric, then watch it sit in a shared drive while the interview happens in a different document. By the time anyone opens the rubric at debrief, the things it was meant to capture are already a memory.
The rubric that moves hiring quality is the one the interviewer never has to remember to use, because it IS the structure of what gets captured.
Get that right and consistency, calibration, and cross-team scaling become the default. The right tooling, including our AI Notes, does the heavy lifting.
Why most rubrics don't change hiring quality
Walk into almost any TA team and you'll find a shared drive full of rubrics: carefully written, role-specific, regularly updated. The hiring outcomes still drift, week after week, because the rubric and the interview happen in different places.
The interviewer holds the conversation. The rubric lives in a tab nobody opens until debrief.
An interview rubric (sometimes called a "hiring rubric" or interview scorecard) is a structured scoring guide for evaluating candidates. The structure on paper is the easy part. The hard part is making the structure load-bearing in the room where the decision gets made.
The failure mode usually shows up as a missing question:
We were missing out on talent. Hiring managers weren't asking about coachability, and we found that they were more likely to reject the candidate than if they had assessed for it.”
The criterion was on the rubric. The interviewer never anchored a question to it, and the rubric couldn't compensate after the fact.
- Rubric lives in a separate document nobody opens mid-call.
- Criteria are on paper, evidence is in someone's head.
- Scoring happens at debrief, days after the conversation.
- Calibration drift surfaces only when an offer falls through.
- Hiring managers form impressions, not evidence-based ratings.
- Rubric structures the notes captured during the call.
- Evidence slots into competencies automatically, with timestamps.
- Scoring happens in the room while the signal is fresh.
- Calibration drift surfaces in Reports, role by role.
- Decisions stand on evidence anyone can replay.
The shift on the right is the whole post. Everything below is the move that gets you there.
What makes a rubric load-bearing
Before the workflow piece, a quick word on construction. A rubric only carries weight when four things are true at the same time, and most rubrics nail three of them. The four:
- Four to six competencies per role. Past eight, interviewers can't score deeply on any one within a call window. Pick the ones that separate top performers from average for this role, not the company-wide values list.
- A calibrated scale. Usually one to five, with descriptors at each level, written together with the panel before the role opens, not pulled from a template.
- Behavioral indicators. What strong, average, and weak performance looks like on each competency. Without them, "communication: 4" is whatever the interviewer felt at the time.
- A role-specific overlay. IC and manager rubrics share a core (communication, problem-solving, collaboration) and overlay the differences (people leadership, technical depth, scope). The shared core makes calibration possible across panels. The overlay keeps the rubric honest to the role.
The post on building interview scorecards goes deeper on construction. From here, we're focused on what to do with the rubric once you have one.
How to make the rubric the data layer
The workflow below moves the rubric from "document people consult" to "structure the system runs on." Five moves, in order. The earlier you start, the more compounding signal you get from each downstream step.
1. Calibrate the rubric before the role opens
Scoring drift starts at intake. If the panel hasn't agreed what a "4 on problem-solving" looks like before the first candidate walks in, the rubric becomes per-interviewer opinion in a shared template.
The calibration session is 30 minutes, runs once per role, and pays back for the whole search.
2. Anchor the rubric to the questions
A rubric without a question map is a wish list. Each competency needs two to four scenario-based or behavioral prompts that force the candidate to walk through real thinking.
Communication surfaces from how the candidate explains a complex decision under pressure, not from how clearly they answer an introduction question. Problem-solving surfaces from a recent project where the right answer wasn't obvious, not from a hypothetical.
Once questions and competencies are mapped, the interviewer's job gets simpler: ask the question, listen for the evidence, score the competency.
3. Capture against the rubric in the call
Typing during the interview kills rapport. Reconstructing notes after the call loses signal. Notetaker removes the trade-off by capturing the conversation and sorting the output into the panel's calibrated competencies automatically.
When the candidate gives a four-minute answer that touches problem-solving and ownership, both competencies receive their slice of evidence, time-stamped to the moment.
The interviewer isn't typing. They're listening, following up, reading the room. Before ending the call, they can scan the rubric to see every competency has evidence. Anything missing surfaces in the moment, not at debrief.
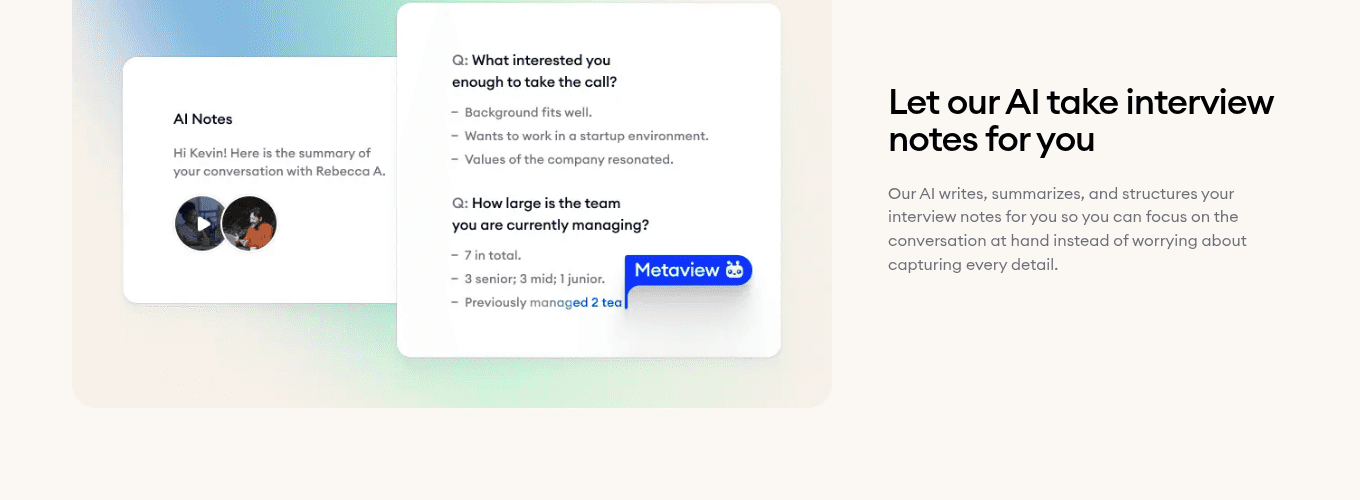
- 1Notes sorted into the competencies the panel agreed on, ready to score.
- 2Each evidence quote is time-stamped to the moment in the call.
- 3Gaps surface as missing competencies before the panel closes the call.
4. Score in the room, not from memory
The 15-second per-competency score, locked at the end of the call, beats a 20-minute reconstruction the next day every time. By the time the candidate leaves, the panel has seen the structured evidence. Scoring becomes a quick read.
This is where bias loses surface area. With evidence quotes sitting under each competency, the score has to match what the candidate demonstrated.
"Strong on culture fit" can't substitute for "scored a four on collaboration because she walked through three concrete examples of conflict resolution."
When the role moves from screening to shortlist, AI Filters inside Application Review let you query the funnel by rubric competency, role-wide.
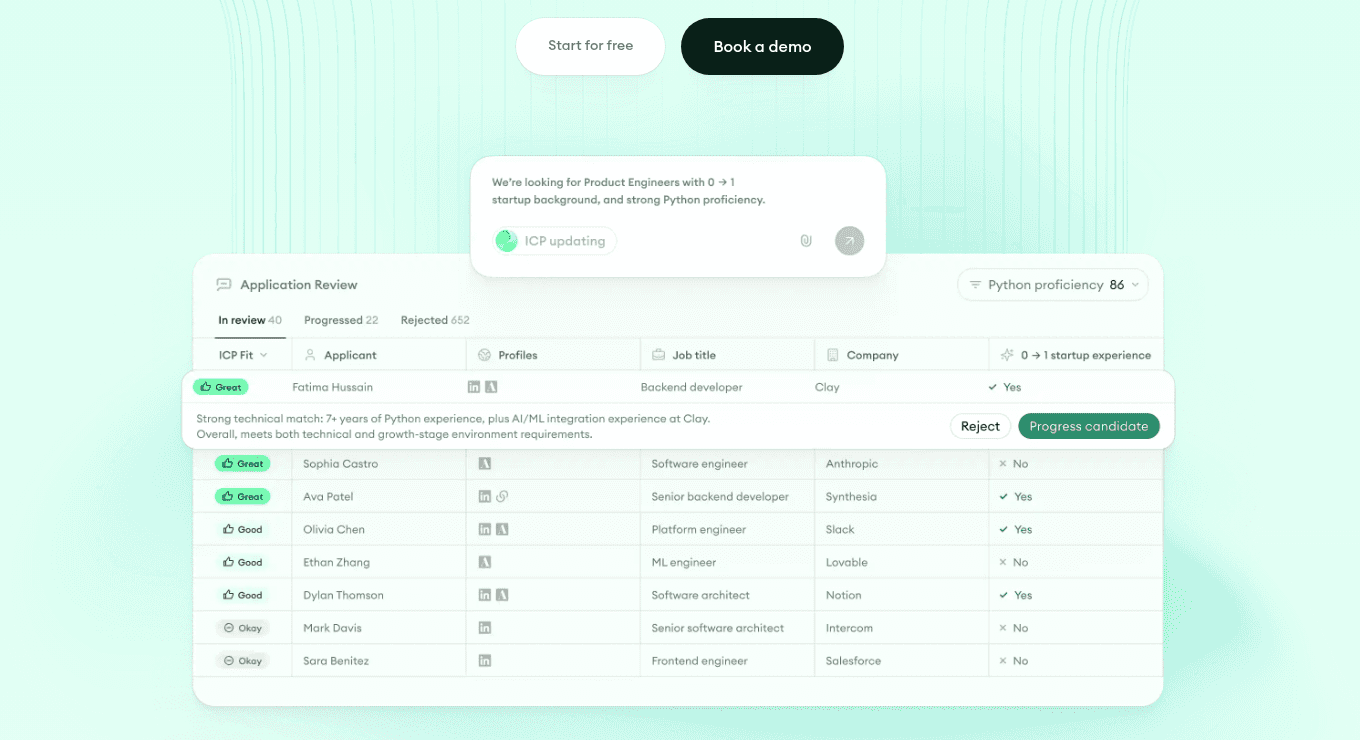
- 1Application Review shows every candidate scored on the same competencies.
- 2Strengths and gaps stack up side by side for direct comparison.
- 3Evidence quotes sit one click below the score, ready to defend a call.
5. Close the loop with cross-interview Reports
One interview tells you about one candidate. A hundred interviews on the same rubric tell you about your hiring system.
Which competencies the funnel consistently underperforms on. Which interviewer scores leniently. Where the rubric is out of step with the role's job description.
Reports turn the rubric into a calibration tool, not just a scoring tool. When a competency runs systematically low across a quarter, the rubric needs recalibration or the sourcing brief needs to change.
When one interviewer's averages drift two points above the panel's, that's a coaching conversation, not a hiring conversation. The patterns turn into specific rubric updates and specific coaching, quarter over quarter, on signal.
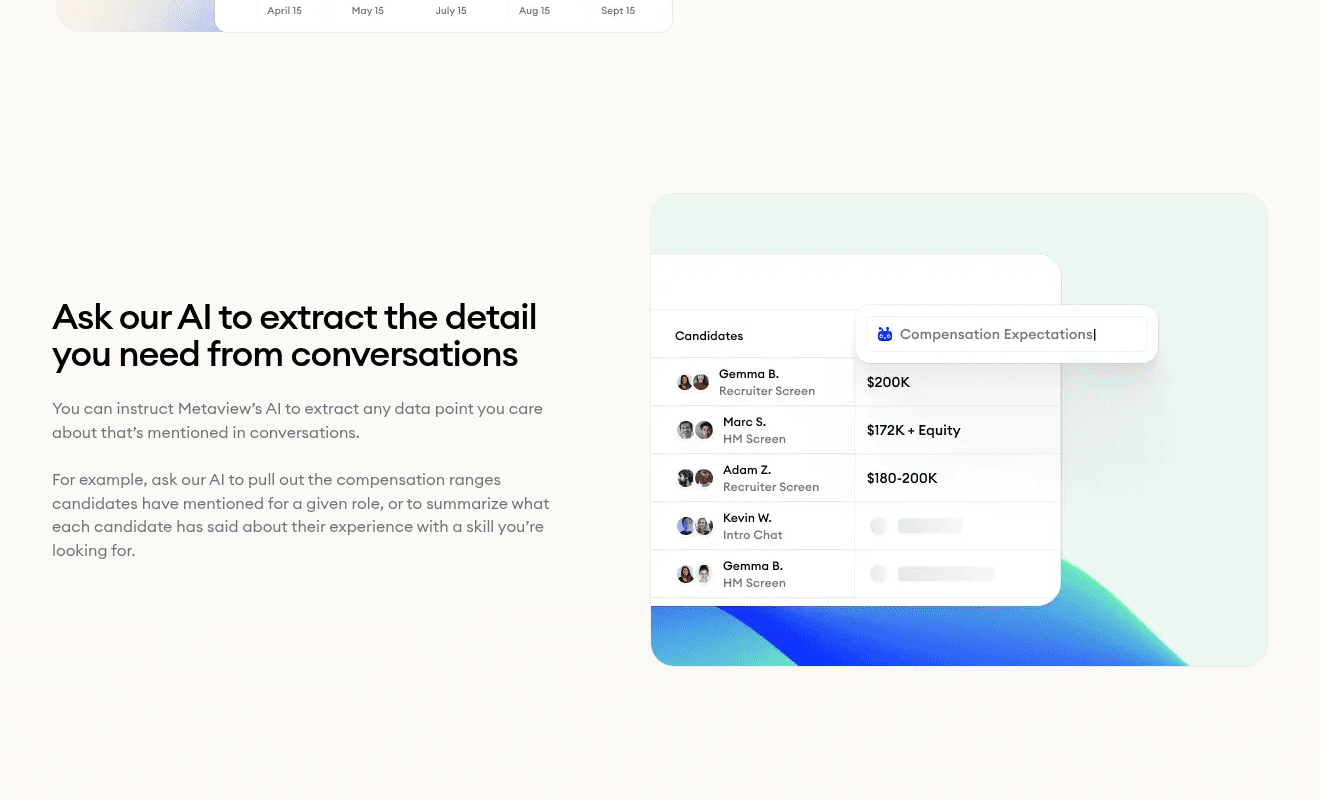
- 1Filter every candidate in the role by any rubric competency score.
- 2Spot competencies the funnel consistently underperforms on.
- 3Compare interviewer averages to catch scoring drift early.
What customers see when the rubric becomes the substrate
Teams that have made the rubric the substrate report the same shift in different language.
Decisions feel more defensible. Calibration disagreements happen earlier, before an offer is on the line. New interviewers come up to speed in days, because the rubric isn't tribal knowledge.
Having these structured rubrics has helped interviewers feel a lot more confident in their decision making. With Metaview, we can move from gut feel to concrete data, visualize patterns, coach accordingly, and make smarter hiring decisions.”
The pattern shows up in the broader data. Metaview's 2026 AI Hiring Alignment Report surveyed 505 recruiting leaders and hiring managers across North America and EMEA.
Teams that put AI at the core of their hiring rate the cross-functional relationship excellent far more often than teams that haven't gotten there yet.
The gradient is the story. Calibrated rubrics, captured automatically, change how recruiters and hiring managers experience the work together.
Run the rubric this way for one quarter and the next sourcing brief writes itself. The candidates who advanced share specific competency signatures. The ones who didn't share specific gaps.
Feed that back into the brief, and the funnel sharpens before you've made the next hire. The substrate persists role to role, while the overlay adapts to each high-volume search.
Frequently asked
How do you keep the rubric from becoming a separate document interviewers ignore?
Make the rubric the structure AI Notes captures into, not a tab interviewers open at debrief. When the rubric is where the evidence lands during the call, using it stops being a discipline question and starts being the default. The shift is from "remember to score against the rubric" to "the score is already there when the call ends."
How many competencies should a rubric carry?
Four to six per role works across most teams we see. Past eight, interviewers can't score deeply on any single one within a call window, so the rubric collapses into surface impressions. Fewer than four and you lose the resolution needed to distinguish between strong candidates.
What's the difference between an interview rubric and an interview scorecard?
In most teams the words are used interchangeably. The closest distinction worth drawing is that the rubric is the standard, written once per role and calibrated by the panel, and the scorecard is the per-candidate completed instance of that standard. The post on creating effective interview scorecards goes deeper on the construction details.
Can the same rubric work for an IC role and a manager role?
Share the competency core, overlay the differences. Core competencies (communication, problem-solving, collaboration) stay consistent so calibration carries across panels. Role-level differences (people leadership on the manager rubric, individual delivery on the IC rubric) live on the overlay. The shared core makes cross-team comparison meaningful. The overlay keeps each rubric honest to the role.
What's the most common rubric mistake that hurts hiring quality?
Skipping the panel calibration session before the role opens. The rubric exists, but the panel hasn't agreed on what each score level looks like in practice, so the rubric becomes per-interviewer opinion in a shared template. Thirty minutes at intake scoring two illustrative answers together is the fix, and it pays back across the whole search.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.



