Quality of hire is a feedback-loop problem: the 4 leading indicators that compress the metric to hours

Most quality-of-hire programs measure the obituary instead of the symptom. They ship a 90-day survey, fold in the first-year performance review, average it with attrition data, and produce a number that arrives a quarter after the decision was made. By that point, the recruiter who made the call is two requisitions deep into the next hire, and the panel that produced the decision is a memory none of the interviewers can reproduce with any specificity. The lagging metric arrives on time. It just arrives too late to change anything.
The signal you actually need to grade hire quality is already on the interview transcript on day one. Whether the panel covered the rubric. Whether two interviewers heard the same answer and scored it differently. Whether the hiring manager’s bar drifted between candidate three and candidate seven. Whether the “great conversation” debrief had any evidence underneath it. All of that surfaces inside 24 hours of the interview, not 90 days after the start date. Most teams just don’t read it.
According to Metaview’s 2026 AI & Hiring Alignment Report - surveying 505 recruiting leaders and hiring managers across North America and EMEA - 85% of companies exceeding their hiring goals use AI in hiring, and 79% of teams with excellent recruiter-hiring manager relationships and high alignment exceed their business goals overall. Only 36% of teams with fair-or-poor relationships and low alignment hit their goals. The teams in the top bucket aren’t outliers, they’re the ones who turned the interview itself into a measurable surface instead of a black box that produces a yes or no. As Amina Darwish, Global Head of Talent at Vercel, puts it on the 10x Recruiting podcast: at her organization, the recruiter scorecard is literally tied to the performance review of every person they’ve hired. The QoH metric and the recruiter’s metric are the same metric.
Why traditional quality-of-hire metrics fail
Most playbooks treat quality of hire as a derivative of three things: 90-day attrition, first-year performance reviews, and a manager-administered survey. Each is downstream of the decision they were built to evaluate. By the time the survey ships, the candidate has been in seat for a quarter, the recruiter has moved on, and the panel that produced the decision is a memory none of the interviewers can reproduce with any specificity. The metric arrives. It just arrives after every interviewer has forgotten the conversation.
The deeper problem is loop length. The recruiter who made the call has no feedback short enough to learn from. The hiring manager has no way to spot whether their bar drifted between candidate three and candidate seven. By the time the QoH dashboard shows a problem, the same problem has already produced ten more hires. That breaks the cardinal rule of any operational metric: the feedback has to arrive fast enough to change the next decision. For QoH to actually drive behavior, the measurement has to happen at the interview layer, not the post-hire survey layer. The interview is when the decision is being made. The interview is where the signal is.
That measurement gap shows up clearly in the Alignment Report numbers. The teams hitting their hiring goals aren’t doing something exotic with AI. They’re using it to shorten the loop between an interview happening and a recruiter being able to act on what the interview produced. Once the feedback arrives inside 24 hours, the rest of the QoH program (calibration, comp ties, miss postmortems) becomes operable. Without that loop length, every other intervention is just another report on something nobody can change.
Our recruiters’ performance is also based on the people they hire. Part of the recruiter scorecard is the performance review of all of the people they’ve hired. You are tied to the quality of people you’re bringing on, that affects your performance and your future compensation.”
Measure QoH at the interview layer, not the post-hire survey
The shift from lagging to leading QoH is conceptual before it’s operational. Stop treating quality of hire as a single trailing score and start treating it as a composite of four signals you can derive from the interview itself, inside 24 hours. Each indicator answers a different question, and together they predict the lagging metric without waiting for it.
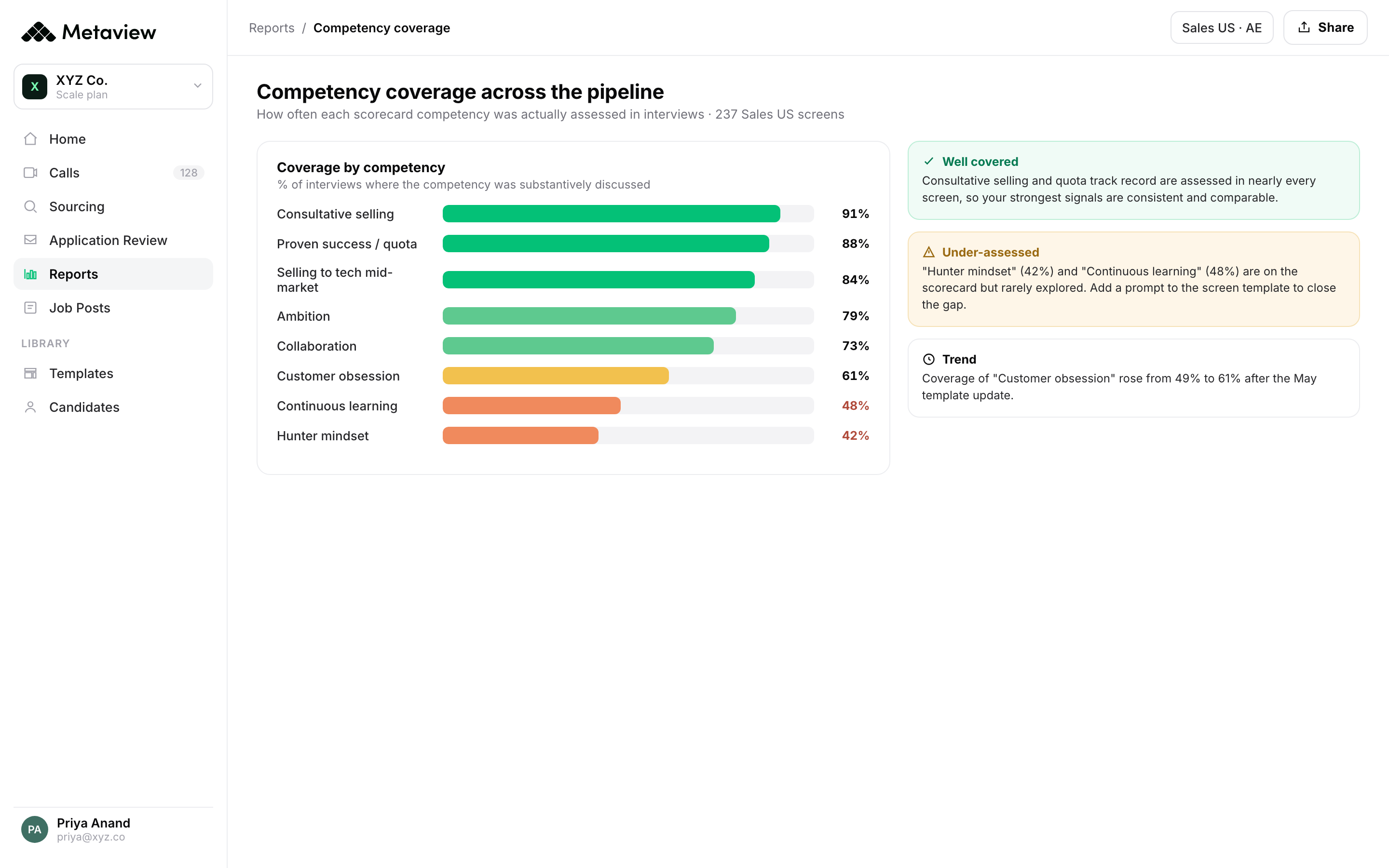
1. Competency capture coverage
Did the panel actually probe every competency on the rubric, or did three of four interviewers default to the same two questions? You can see this on the transcript. When capture coverage is below 60% of the rubric, the rest of the QoH pipeline is guessing. Coverage is the cleanest leading indicator because it’s binary: either the question got asked or it didn’t. And it’s the indicator most easily fixed by the recruiter mid-search.
2. Rubric variance across the panel
If interviewer A scored the candidate a four on “systems thinking” and interviewer C scored them a two on the same competency, the panel didn’t disagree about the candidate. They probably disagreed about what “systems thinking” meant. That gap is the loudest predictor of a bad hire because it surfaces calibration drift in the same week you can still fix it. Run a calibration session every two weeks and you’ll watch the variance compress in real time.
3. Decision defensibility per stage
For every advance or pass decision, the question is whether someone outside the room could reconstruct the reasoning from the transcript and scorecard. If the answer is “no”, if the decision is logged as “vibes” or “great conversation”, you have a QoH risk on that stage. The risk recurs because the panel hasn’t named the criterion they were actually evaluating against. Capture-layer signal makes defensibility a measurable property of every interview, not an audit you run once a year.
4. 90-day retro as a calibration target, not the primary metric
The lagging metric still has a role, as a calibration target for the leading metric. Pull the scorecards of the last 20 hires, segment them by performance at 90 days, and look for the patterns. The interviewers who systematically over-scored on “ownership” but under-scored on “communication”, that’s where calibration time goes. The 90-day data isn’t useless. It’s just the back-test for the leading model, not the model itself.
Five strategies that actually move the metric
Once measurement is wired at the interview layer, these are the five interventions that produce the biggest swing on the trailing metric. Strategies one and two raise the floor, strategies three through five raise the ceiling. The sequencing matters: don’t skip ahead to comp-ties before the rubric and capture layer are in place, or you’ll be tying recruiter outcomes to a metric they can’t see.
1. Define success in writing before kickoff
The Alignment Report shows 68% of searches start with high alignment when AI is core to hiring, vs 49% without it, a 40% lift on the same metric. The mechanism is unglamorous: a job spec that names the three competencies that matter most, ordered, with example signals for each. If the recruiter and the hiring manager can’t agree on the ordering before sourcing starts, the panel won’t agree at debrief either. Calibration drift starts at kickoff.
2. Capture every panel competency the same way every time
A structured scorecard isn’t a forms exercise. It’s the only way to compare candidates apples to apples. The fastest implementation is to let capture happen automatically (notes generated from the conversation, scored against the rubric), then let interviewers tighten the language rather than writing from scratch. The capture-first model produces more honest scorecards than the write-from-scratch model. Interviewers who write from memory rationalize what they wish they’d asked.
3. Calibrate against your own hires, not external benchmarks
Calibration sessions where the panel re-scores three recent hires they all interviewed together are worth more than any external benchmarking. The drift you uncover is your drift. Six panel members in a room re-scoring three hires will surface the rubric ambiguities that no spec rewrite would have caught. Run one calibration session per panel per month and the variance number from indicator two will compress by half inside a quarter.
4. Tie recruiter and hiring manager comp to QoH outcomes
This is the strongest possible signal that the organization takes hire quality seriously, and the strongest change in which candidates recruiters surface. At Vercel, recruiters are scored partly on the performance reviews of the people they’ve hired. The downstream effect is that the recruiter stops optimizing for time-to-fill alone and starts optimizing for time-to-impact. Both metrics improve, because nobody on the recruiting team can shortcut one without the other showing up on their own scorecard.
5. Close the loop on every miss
For every hire that underperforms at 90 days, walk back the transcript and find the moment the signal showed up. Sometimes it was a question that didn’t get asked. Sometimes it was a four that should have been a two. Sometimes it was a panelist who consistently scored their interview’s competency one point higher than the rest of the panel. The pattern across 20 misses is your improvement plan for the next 100 hires. The work is unglamorous, but it’s the only loop that actually compounds.
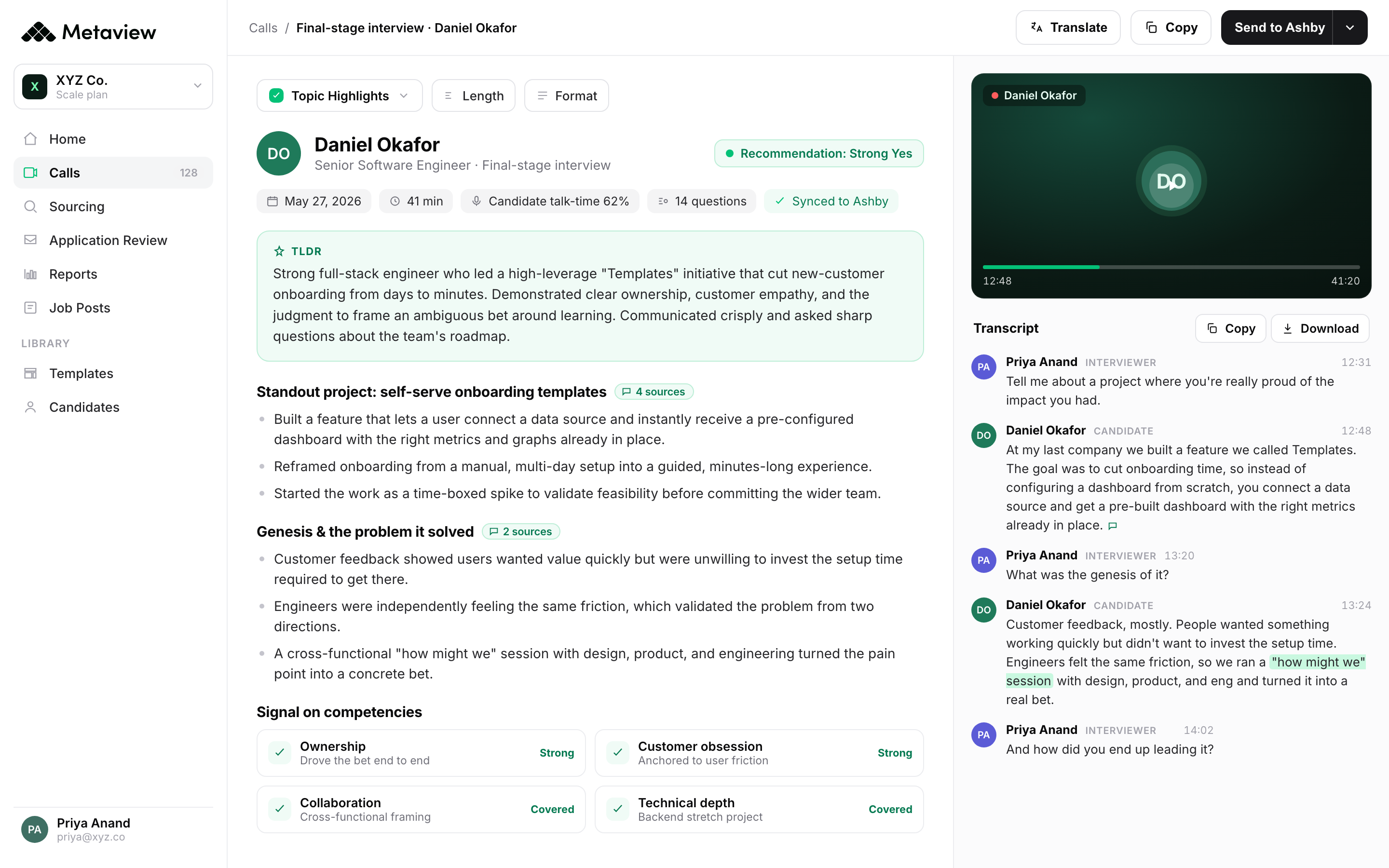
Lagging vs leading: the comparison TA leaders actually need
For TA leaders briefing exec stakeholders on the QoH program, the comparison that lands is binary. Lagging QoH gives you a number that’s correct and useless. Leading QoH gives you a number that’s directionally noisier but actionable in the current quarter. The gap between the two isn’t about precision, it’s about loop length. Precision without timeliness is just record-keeping.
- Arrives a quarter after the decision was made.
- Confounded by onboarding, manager fit, and team context.
- Response rates drop the longer the lookback.
- Feedback loop too slow to change recruiter behavior.
- Per-recruiter cohorts never reach significance.
- Available the day after the interview.
- Cleanly attributable to the panel and the rubric.
- 100% coverage on every interview.
- Recruiter sees drift in real time.
- Calibration on individual interviews, not cohorts.
What this looks like in practice
The companies that have actually moved their QoH number talk about it less as a measurement problem and more as a feedback-loop problem. On the 10x Recruiting podcast, Laura Barnes, VP of TA at Flock, walks through how her team measures hire quality without creating an environment where recruiters are afraid to surface negative signal. That fear is the second-most-common reason QoH programs fail. The first is loop length.
The line that lands hardest from that conversation: QoH is solvable as soon as you stop treating it as a recruiter scorecard line item and start treating it as the organization’s measure of whether the interview did its job. Once the interview itself is the unit of measurement, every downstream metric (offer accept, ramp time, performance review variance) gets a leading indicator attached to it that the recruiting team can actually move.
As a recruiter, you often work with hiring managers who are less experienced in hiring, or new to hiring. Being able to structure their questions and give them guidance on what they should be asking, which is then represented in the scorecard and their notes, makes that more consistent.”
 Metaview
MetaviewYour 4-week QoH measurement loop
This is the operating tempo. By week four, you have a measurement system, not a retrospective. Run it on your two highest-volume reqs first, then expand to the rest of the funnel once the loop is producing data the recruiters can act on.
- Week 1, Define. Write the competency rubric for your two highest-volume reqs. Rank competencies, define signals for each one, and get the hiring manager to sign off in writing. The signed-off document is the calibration target, not the spec.
- Week 2, Instrument. Turn on capture for every interview on those two reqs. Configure the scorecard inside the tool so scoring happens against your taxonomy, not a generic one. Every interview from this point forward is a data point.
- Week 3, Calibrate. Run one calibration session per panel using three recent hires the team interviewed together. Quantify the drift in writing, not in conversation. The session output is a table of competency-by-interviewer scores, not a meeting recap.
- Week 4, Close the loop. Cross-reference 20 recent hires’ scorecards with their 90-day performance signals. Surface the systematic over-scorers and under-scorers by competency. This is the calibration target for the leading indicators.
- Ongoing. Treat the QoH dashboard like a sales pipeline review, weekly cadence, not quarterly. The metric only changes behavior if the team looks at it as often as they look at funnel conversion.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync, set up in under 10 minutes.
Frequently asked
Is quality of hire a leading or lagging metric?
Both, depending on where you measure it. Post-90-day surveys and first-year performance reviews are lagging. Interview-layer signal (competency capture coverage, rubric variance, decision defensibility) is leading and arrives the day after the interview. The fast feedback loop is the one that lets you fix QoH in the current quarter rather than next year’s headcount plan.
What’s the difference between a 90-day check and capture-layer signal?
The 90-day check tells you whether the hire is working out. Capture-layer signal tells you whether the interview did its job. The first is downstream of dozens of variables (onboarding, manager, team fit) that have nothing to do with the hiring decision. The second is cleanly attributable to the panel and the rubric, so it actually drives a change in recruiter and interviewer behavior.
Can you measure quality of hire without surveys?
Yes. The leading indicators (competency capture coverage, rubric variance across the panel, decision defensibility per stage) are derivable from interview transcripts and structured scorecards. Surveys remain useful for calibration, confirming that scorecards predicted performance, but they shouldn’t be the primary QoH instrument because they arrive too late to change behavior in the current hiring round.
How does Metaview fit into our existing ATS?
Metaview connects to the major ATSes (Greenhouse, Lever, Ashby, Workday, and others) so capture happens automatically on every scheduled interview and the structured scorecard syncs back to the candidate record. Candidate consent is built into the ATS invite, so the panel doesn’t add steps and the recruiter doesn’t add manual logging.
How long until we see a quality-of-hire signal we can act on?
One full hiring round at the team level, typically two to four weeks, is enough to see capture coverage and rubric variance for that team. Cross-cohort patterns (the firm-level QoH dashboard) take 20 hires or more to stabilize. The first week is when calibration starts; the first quarter is when the lagging metric finally catches up to confirm what the leading metric already said.



