Hiring at scale is a signal problem, not a volume problem: the 4 inputs that compress cycle time without adding headcount

Most "hiring at scale" guides start by counting candidates. Pipeline volume up 3x. Open reqs up 40%. Applications per role climbing into the hundreds. The implicit framing: scale is a volume problem, and the fix is to triage faster.
The framing is wrong, and the data backs it. Recruiting teams that try to scale by adding throughput end up with bigger funnels, longer cycle times, and the same hiring-manager friction they started with. The teams that compress cycle time without adding headcount do something different. They treat scale as a signal problem, not a volume problem, and they invest in the data layer underneath the interview, not the speed of the funnel above it.
This piece walks through what that shift looks like in practice. The four inputs that turn scale from chaos into a system. The 3-column comparison that shows where spreadsheets and legacy ATS stop being enough. And the 30-day audit any TA leader can run to find which of the four inputs is leaking the most time today.
Why hiring at scale looks like a volume problem (and isn't)
Scale shows up first as volume. More applications per role, more interviews per recruiter, more reqs per hiring manager. The instinct is to add capacity: another recruiter, another sourcer, another assessment tool to pre-filter the inbox. That instinct works for about two quarters. Then it stops.
It stops because the funnel was never the bottleneck. Look at where time actually disappears in a scaling TA org and the pattern is consistent. Interviews end. The recruiter writes up half a scorecard during a 5-minute gap before the next call. The hiring manager reads the scorecard two days later, asks a question the recruiter cannot answer because they cannot remember, and the decision gets deferred a week. Repeat across 30 interviews a month and the funnel does not need more throughput. It needs the data inside each interview to outlive the meeting it happened in.
According to Metaview's 2026 AI & Hiring Alignment Report - surveying 505 recruiting leaders and hiring managers across North America and EMEA - 90% of teams rate their working relationship as good or excellent, yet only 27% say they rarely consider working around their counterpart. The surface and the reality diverge most sharply at scale. The bigger the org, the more interviews per week, the wider the gap between “good on paper” and “good in practice.”
The reframe is what unlocks the leverage. Scale is a signal problem. The four inputs below are the ones that decide whether your TA org compresses cycle time as it grows, or just adds headcount to absorb the friction.
The problems most companies have with recruiting are not ‘we have this flood of applications and we need to evaluate people more efficiently.’ That is probably not the problem most companies will have in the future as headcount diminishes and the best people have more options.”
The 4 inputs that compress cycle time without adding headcount
The four inputs are not exotic. Every TA leader already talks about them. The difference is whether they get instrumented or estimated. Instrumented means the data sits in a system the next person in the chain can read. Estimated means it lives in the recruiter's head until the next status meeting.
Each input maps to a different scaling failure. Signal capture decides whether the panel is actually evaluating the same thing across 30 candidates. Cross-team alignment decides whether week 8 of a search is fighting the same battle as week 1. Candidate experience decides whether the people you actually want come back when you call. Single source of truth decides whether your TA org is one connected system or a federation of recruiter notebooks.
Input 1: Signal capture across interviews
Signal capture is the input that breaks first at scale. With five recruiters and one hiring manager, scorecards stay consistent because the people involved talk to each other every day. With twenty recruiters and forty hiring managers, the variance explodes. Some panels probe four competencies. Others probe one. Some write three bullets per interview. Others write a paragraph. The data the rest of the system runs on stops being commensurable.
The fix is not a more elaborate scorecard template. Templates already exist in every ATS and most of them get ignored under interview-load pressure. The fix is making the interview itself produce structured evidence: competency-by-competency capture, with named questions, sample answers, and follow-up prompts, generated as the conversation happens rather than reconstructed after it.
Input 2: Cross-team alignment on requirements
Cross-team alignment is the input the 2026 Alignment Report calls out most directly. Teams where AI is core to hiring see a 40% increase in initial alignment at search kickoff versus teams that don't use AI at all. The mechanism is not magic. It is that the kickoff stops being a single 30-minute meeting and becomes a continuous data feed: every interview reinforces or revises the criteria, and the recruiter and hiring manager are reading the same evidence each time they meet.
At scale this matters because the kickoff-to-debrief gap is where searches drift. Without a shared data layer, week 6 of a search is operating on week-1 assumptions. The candidate definition has changed. The hiring manager's priorities have shifted. Neither side has the bandwidth to re-align in real time. Searches stall, candidates churn out, and the post-mortem blames "fit."
Input 3: Candidate experience through panel coordination
Candidate experience compounds at scale in both directions. A great experience produces referrals, faster offer acceptance, and year-one retention that pays back the recruiting spend. A poor experience produces a Glassdoor review, a quietly evaporating pipeline, and the same candidate avoiding your brand the next time a role opens. The dollar value of either outcome is real and rarely shows up in the time-to-fill spreadsheet.
The lever at scale is panel coordination. Candidates form most of their impression of a company in the first two minutes of an interview: were the interviewers prepared, did they ask consistent questions across the loop, did they actually listen, did feedback come back fast. When recruiters have to take notes and ask follow-up questions at the same time, the experience suffers in a way the candidate can feel. The cost gets paid two quarters later in offer acceptance rates.
Input 4: Single source of truth for decisions
Single source of truth is the input that ties the other three together. Without it, signal capture lives in one tool, alignment data in another, and experience metrics in a survey nobody reads. With it, the recruiter, hiring manager, and finance partner are all reading from the same evidence trail and the conversation moves from defending cost-per-hire to defending revenue-per-hire.
The data layer does not require ripping out the ATS. Most scaling TA orgs already have an ATS that handles the structural workflow well. What they are missing is the qualitative interview data the ATS was never designed to capture: who said what, which competencies actually surfaced, where the panel converged or split. That is the layer interview intelligence fills in, and it sits underneath the ATS rather than replacing it.
Single source of truth: connecting interviews to decisions
A single source of truth is the operational version of the Report's headline finding. Teams using AI in hiring are 3.8x more likely to rate their cross-functional relationship as excellent, and the mechanism is shared data. When the recruiter and the hiring manager look at the same interview evidence, the same competency-by-competency capture, and the same per-stage decision log, the conversation about a candidate stops being adversarial. Both sides are arguing about the same artifact.
In practice this looks like an instrumented interview layer connected to every existing hiring tool. The ATS still handles requisitions, candidates, and offers. The scheduling tool still books interviews. The compensation tool still owns bands. What changes is that every interview output - the structured notes, the competency capture, the hiring-manager debrief, the cross-panel summary - lives in one place that everyone can read, and pushes structured signal back to the ATS so the audit trail is complete.
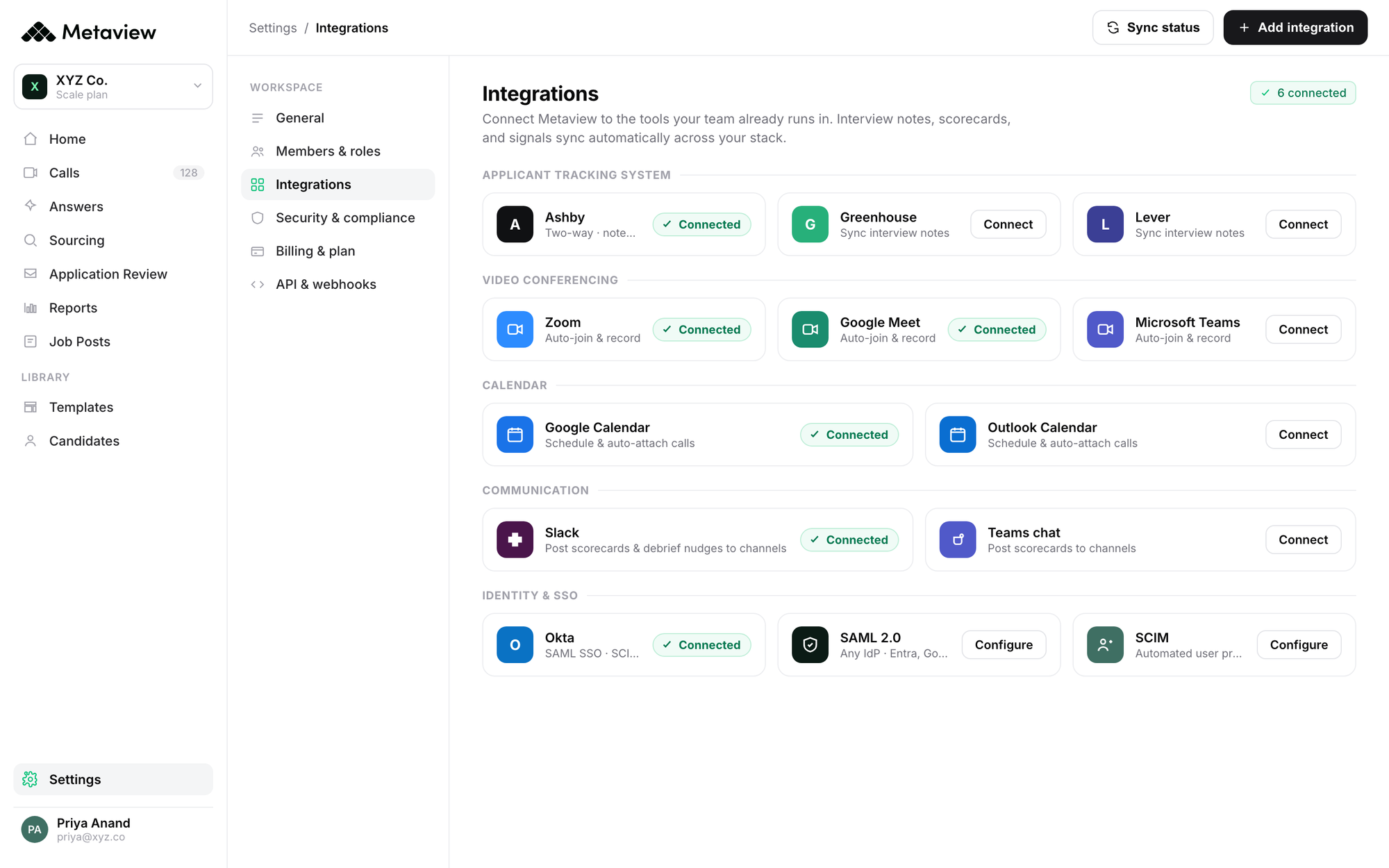
The screenshot below shows the integrations grid that does the connecting. Cockroach Labs, Quora, Brex, Vercel, and every other org cited elsewhere in this article connect Metaview to their existing stack rather than replacing pieces of it. The principle: do not make scaling TA harder by ripping and replacing. Add the data layer underneath what already works.
Manual vs legacy ATS vs Metaview, head to head
The 3-column comparison below is the version of this argument finance teams want to see. Spreadsheets and legacy ATS each handle a piece of the scaling problem well; neither captures the qualitative interview data the four inputs depend on. Metaview is the layer that fills the gap, not a replacement for what your team already uses.
| Dimension at scale | Spreadsheets | Legacy ATS | Metaview |
|---|---|---|---|
| Captures full interview content | Whatever each interviewer types after the call | Free-text notes field, no structure | Every interview transcribed, structured, and competency-tagged in real time |
| Standardizes evidence across panels | Inconsistent by definition | Template lives in the ATS, gets ignored under pressure | Structured capture happens during the interview, no post-call reconstruction |
| Surfaces cross-team alignment | Lives in a separate doc, drifts immediately | Job description is the only shared artifact | Per-stage decision evidence the recruiter and HM both read |
| Measures candidate experience | Quarterly survey at best | Stage-level NPS, no causal data | Per-interview signal on interviewer prep, question consistency, follow-up speed |
| Compresses cycle time without headcount | Adds an admin layer | Saves clicks, not days | Saves days per candidate by removing the post-interview reconstruction step |
| Connects to the existing stack | Manual export-import, breaks weekly | Closed to qualitative data | ATS sync plus open API, signal flows both ways |
Standardize at scale, calibrate continuously
Standardizing at scale is the input most teams confuse with discipline. They roll out a template, mandate it in the interviewer training, and assume consistency will follow. It does not. Templates compete with interviewer style, time pressure, and the candidate's own conversational momentum. By month three the consistent ones are using the template; the rest are back to free-text notes with apologies.
The way to actually standardize is to make the structure happen during the interview, not after. Each conversation gets transcribed and competency-tagged in real time, and the recruiter sees the structure assemble itself as they listen. The discipline does not depend on the interviewer remembering the template; the system has the template. The interviewer has the conversation.
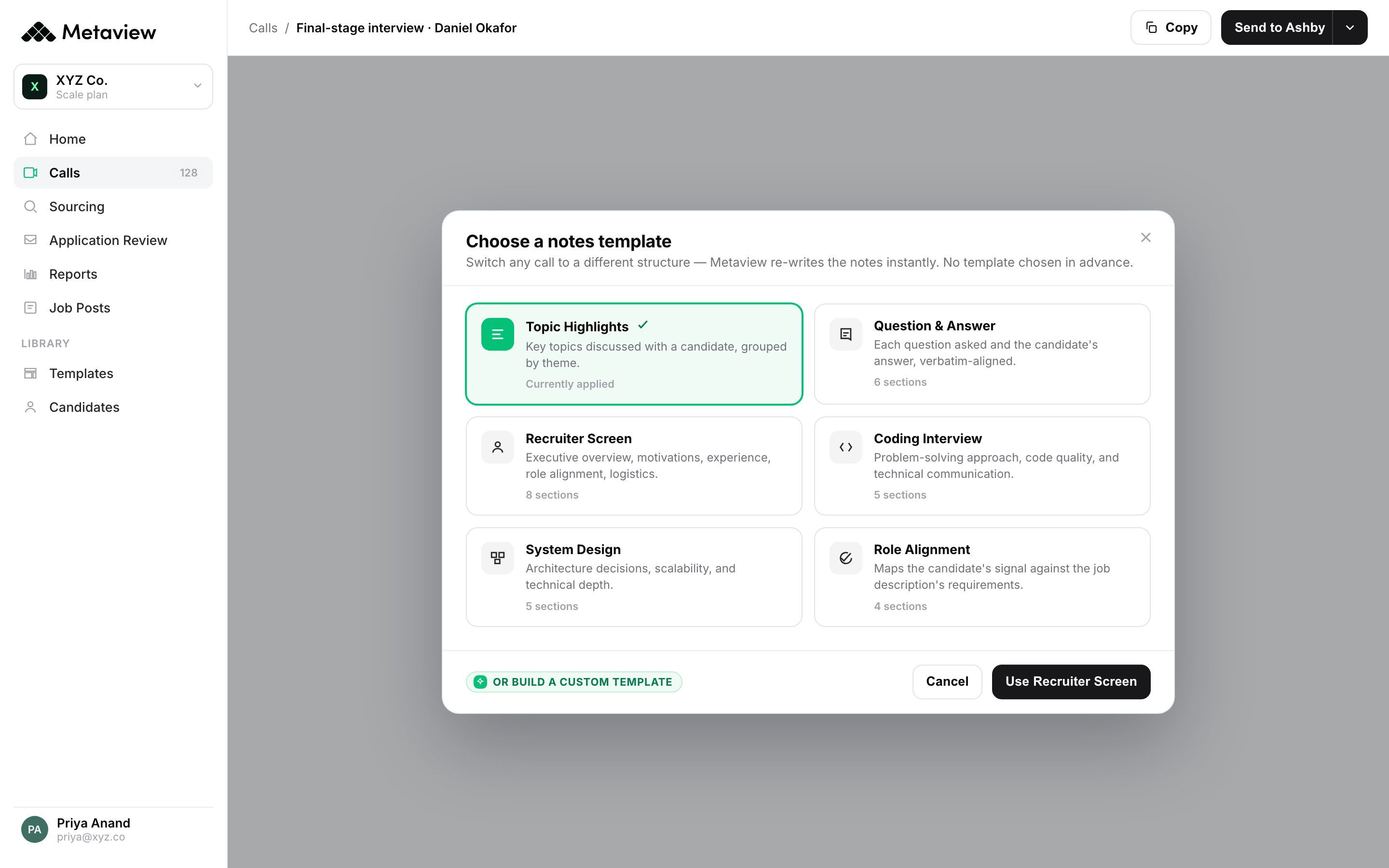
Calibration is the other half. Once every interview produces commensurable evidence, panels stop drifting. The hiring manager can see which interviewers consistently surface stronger signal on which competencies, where the panel converges, and where it splits. That feedback loop - panel-level consistency, surfaced weekly rather than discovered at year-end - is what keeps the quality bar from sliding as the team scales.
With Metaview, our recruiting team has saved over 14 full work weeks.”
30-day audit: where to look first
A 30-day audit beats a 12-month transformation because it forces the team to look at real interviews from the last month and classify them against the four inputs. Most teams discover that one of the four is the obvious bottleneck, and fixing just that one frees up a week of recruiter time. The plan below is the minimum viable version: five workdays per week, no new tooling category, no headcount additions.
- Week 1, audit the inputs. Pull every interview from the last 30 days. For each, mark whether the four inputs were captured at all. Most teams discover signal capture and single-source-of-truth are the inputs missing, and alignment is captured only at kickoff.
- Week 2, fix the bottom quartile. Pick the 25% of interviewers whose post-interview output is hardest to read. Onboard them onto a structured-capture flow. Aim for consistency, not perfection. Every interview from week 2 onward needs to produce competency-by-competency evidence the next person in the chain can act on.
- Week 3, instrument the data layer. Connect interview output to the ATS so the audit trail is in one place. Build a one-page dashboard with the four inputs, segmented by recruiter and hiring manager. Share it with hiring managers before sharing it with leadership. Their feedback in this week tells you which input matters most.
- Week 4, ship the calibration loop. Run a 30-minute panel-calibration session using the actual interview evidence from weeks 1-3. The aim is not to discipline outliers. It is to show the panel where their signal converges and where it diverges, and to agree on which competencies the team will tighten next month. Repeat monthly.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.



