Contrast bias: when the queue replaces the rubric

Day four of the sprint. You're on screen six of the day. A candidate walks through how they shipped a difficult release on a compressed timeline, and the question that surfaces first isn't does this meet the bar? It's better than the last one.
That's contrast bias announcing itself. The moment the comparison reference shifts from the role to the candidate in the previous chair, the evaluation has drifted. By the end of the day, the rubric is doing less work than the memory of the queue.
Contrast bias is rarely the result of bad interviewers. It's the predictable consequence of running back-to-back evaluation under cognitive load, with no anchor that resets between conversations. Below: how it shows up, why awareness training can't close it, the sequencing discipline that closes the gap, and where Metaview's data layer makes the fix auditable.
Why contrast bias is the trigger condition for unfair hiring
Most recruiting teams treat bias as a self-awareness problem. The fix is presented as training: get the panel to recognize affinity, halo, recency, contrast. The training is real. The recognition is genuine. The bias keeps showing up anyway because contrast is mechanical, not behavioral.
When evaluations run back-to-back, the brain anchors each new candidate against the most vivid recent one rather than the rubric criteria the team agreed on in the kickoff. By the third or fourth interview in a stretch, comparison takes over from evaluation. The rubric is still on the screen. It's not doing the lift any more.
This is also where contrast bias becomes the temporal amplifier on every other bias the team is already fighting. Affinity, confirmation, halo, and recency all compound when the comparison reference moves from the role to the queue. A panel can be well-calibrated on a single candidate and badly drifted by mid-afternoon, with no individual interviewer doing anything obviously wrong.
According to Metaview's 2026 AI Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, the consequence shows up as a wide outcome gap. Teams whose partnership and process hold together hit very different numbers from teams where both are fraying.
That gap between 79% and 36% is what private-impressions hiring costs at the team level. Order-effect bias is one of the specific ways the gap opens. Two evaluators looking at the same candidate, with the same rubric in front of them, can land on different scores depending on whether the morning queue was sharp or weak. The rubric stops working exactly when you need it most.
How contrast bias shows up: three scenarios to recognize
Contrast bias rarely announces itself with a clean tell. It shows up as three specific behaviors that look normal from inside the moment and obvious from outside it. Spotting the three signals as they happen is the work the sequencing discipline rests on.
1. Comparison language in the room
The first sign is verbal. Interviewers describing candidates by reference to other candidates, not to the role criteria. Sharper than the last one. Quieter than the morning slot. More structured than the panel from yesterday. The bar implied in each sentence is the previous interviewee, not the rubric anchor.
The reset is conversational and uncomfortable. When the comparison phrase lands in a debrief, ask the speaker to restate against the rubric. Not "better than" but "scored a 3 on signal-X because they did Y." If the rubric translation is hard, the read was running on comparison.
2. Score drift correlated with order, not with quality
The second sign is statistical. Same interviewer, same rubric, same role: scores trend down across the day for everyone, or trend up, or wobble in patterns that map to the queue rather than to candidate strength. After hour three of back-to-back interviews, the same answer gets a different rating depending on what came before it.
This pattern is invisible to the interviewer in the moment and visible across the corpus. Pulling the per-interviewer score distribution against interview start time, then against candidate competency evidence, shows the drift cleanly. Score drift correlates with order when contrast bias is doing the rating work.
3. Debrief anchoring on whoever was discussed first
The third sign is structural. Whichever candidate the panel opens the debrief on becomes the implicit baseline. Everyone subsequent is rated relative to that opener, not against the role. By the time the third candidate comes up, the conversation is comparing three people to one.
The reset is order-of-discussion discipline. Run the debrief one candidate at a time, scorecard-first, without crosstalk on candidates the panel hasn't gotten to yet. Open with the candidate who triggered the most internal disagreement, not the one who interviewed first. That single move collapses anchoring on the opener and forces the rubric back into the foreground.
The sequencing discipline that closes the contrast gap
Four moves close the contrast gap. None require new training. Each requires a discipline most teams skip when the calendar is full. Compounding is the point. Each move makes the next one easier to hold, and the data layer that captures all four turns the discipline into a system you can audit.
1. Anchor the rubric before the interview, not during
The most impactful move is also the one teams skip most often. Before the conversation starts, the interviewer writes the anchor for each rubric criterion: what a 1, 3, and 5 looks like in concrete behavior for this candidate's specific résumé. Not the generic competency definition, the role-specific candidate-specific version, two minutes of work per criterion.
The anchors travel into the room. When the comparison instinct fires mid-interview, the interviewer has the role-anchored bar at hand instead of reaching for the queue.
2. Capture evidence in the room, not at end-of-day
Memory fades by the third interview of the day. By the fifth, it's reconstructed from impression rather than evidence. The window for accurate capture is the conversation itself, not a debrief block at 5pm where the interviewer is recalling six candidates in sequence.
Capture that lives next to the rubric, in the moment, is the single biggest defense against contrast drift. With Metaview's AI Notes, the capture is automatic and rubric-anchored. The interviewer leaves each conversation with the evidence already organized against the role's criteria, not against the previous candidate.
3. Independent first-pass review before any panel discussion
Calibrated panels close some forms of bias, but they amplify contrast bias when the order of voices in the room sets the anchor. The first hiring manager to speak frames the rubric for everyone after them, and structured calibration becomes a negotiation around the first impression.
Independent first-pass review breaks that loop. Every panel member submits a rubric-anchored scorecard before the debrief opens. Disagreements surface from written evidence, not from social order in the room. The debrief becomes where disagreements get resolved against the rubric, not where they get rationalized into consensus.
4. Cross-interview drift detection
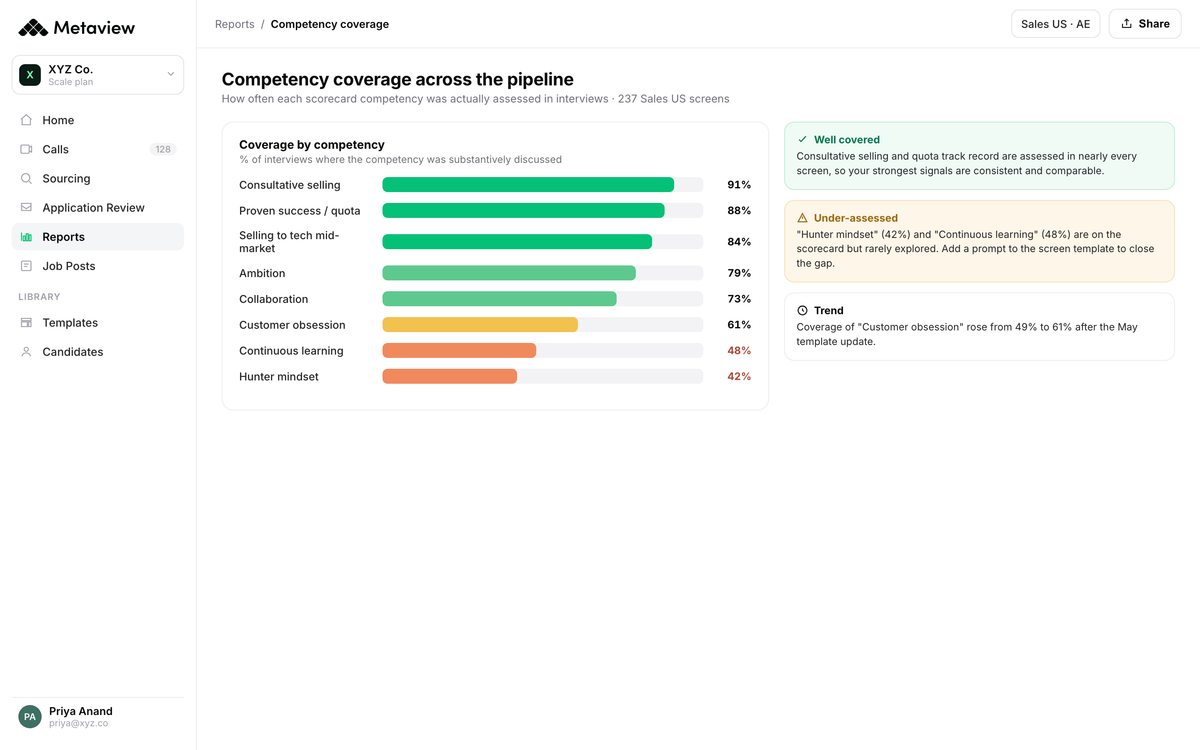
Steps 1 through 3 work the inside of a single interview. Step 4 widens the lens. When every interview is captured against the same rubric, scoring patterns aggregate cleanly enough to surface order-effect drift at the system level, the layer no individual interviewer could see from inside the day.
Does this interviewer rate communication 1.5 times harsher on candidates who follow a strong morning slot? Does the panel's average score swing 0.7 points between Tuesday morning and Friday afternoon for the same role? These patterns don't show up in any single debrief. The data layer surfaces them across the corpus, where Reports turns suspicion into evidence.
This is what the structured-notes view looks like when AI Notes is anchoring the read against the rubric so the next interview doesn't run on memory of the queue.
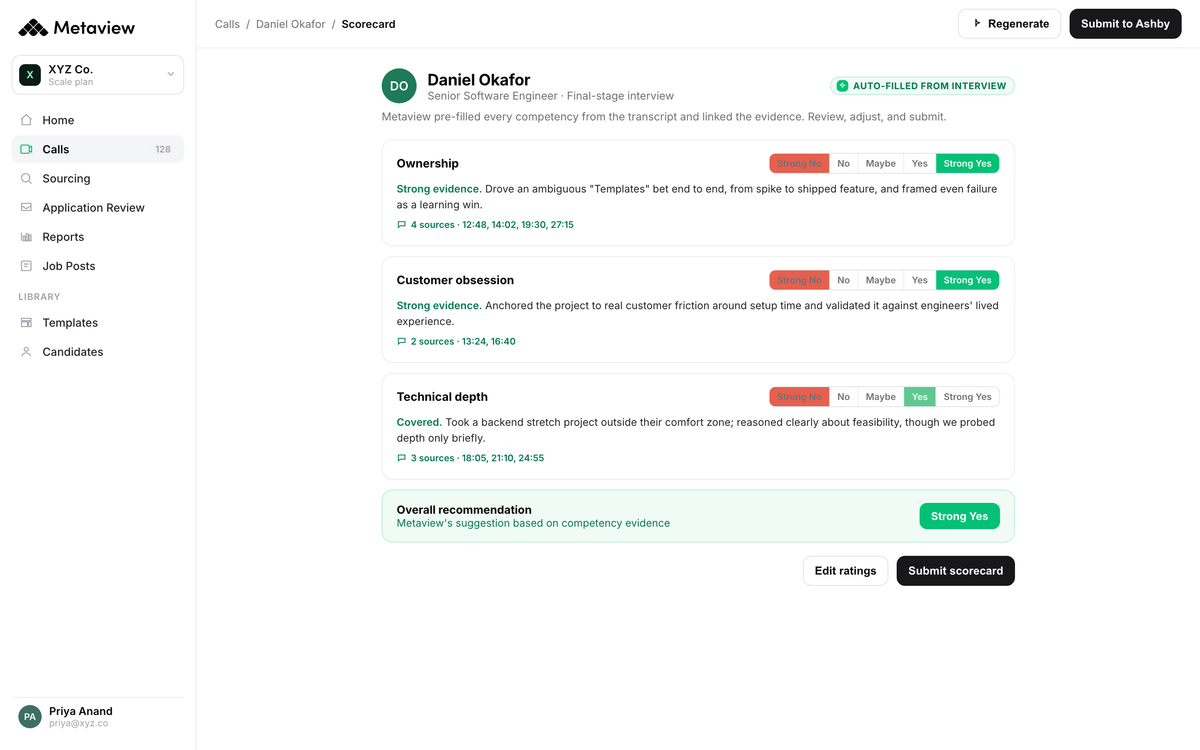
Each move compounds the next. The pre-interview anchor sharpens the in-room capture. The captured evidence makes the independent pass meaningful. The aggregated record makes drift detection possible. Run them as a system and the contrast effect that used to live in private memory becomes evidence the team can audit.
We use the multi-source feature so each interviewer goes in unbiased but informed enough to cover new ground.”
How we built this into the workflow
Discipline gets you most of the way. The capture layer that turns each move into evidence is what lets the team audit the result and catch the drift before another quarter ships under it. Our product carries three jobs: anchor before, capture during, audit after.
- Scorecards arrive hours later, reconstructed from memory of the queue.
- Each interviewer carries a different rubric anchor into the room.
- Debriefs anchor on whoever was discussed first.
- Order-effect drift stays invisible at the team level.
- Every interview lands as structured evidence against the role's rubric.
- The rubric travels with the candidate, not with the interviewer.
- Independent rubric scorecards land before the debrief opens.
- Cross-interview drift surfaces in Reports before it ships another quarter.
The cross-interview view is the layer most teams have never had access to. Reports aggregates the structured evidence across interviewers, roles, and time, so the order-effect drift that used to live in private suspicion becomes visible at a glance. Audit replaces anecdote.
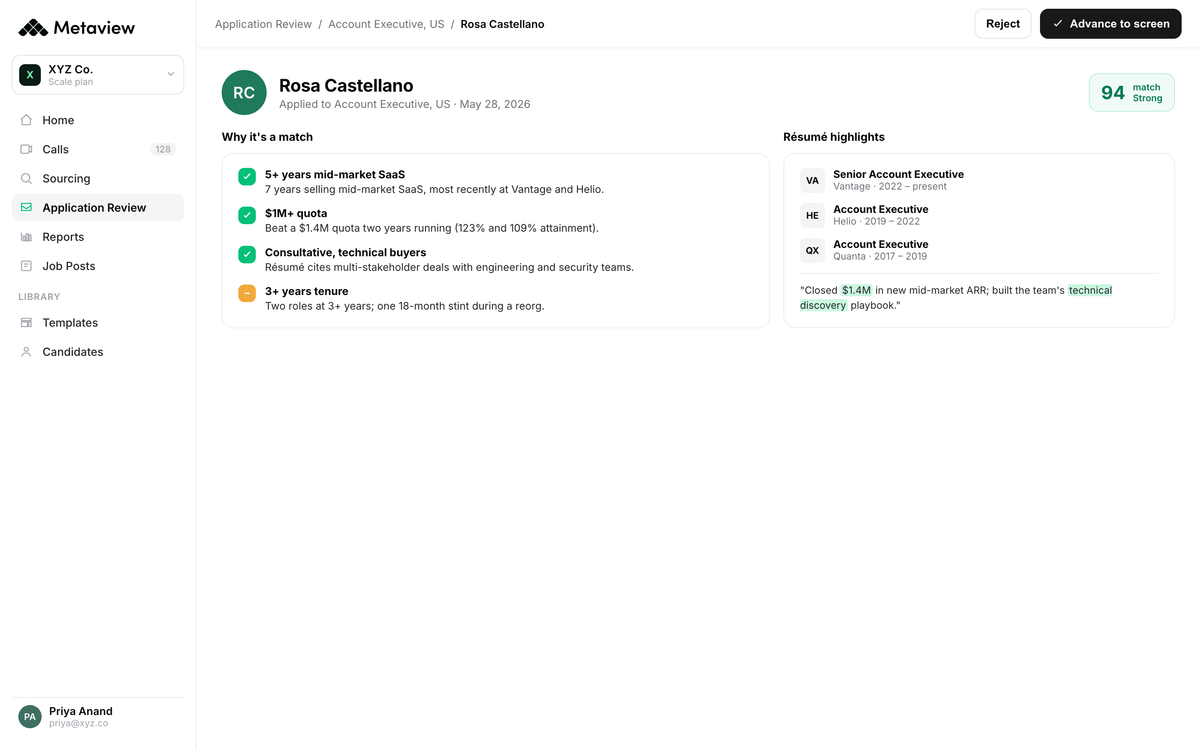
The rubric anchor that travels with the candidate starts further upstream. Application Review scores every inbound application against the role's criteria, with the reasoning trail attached, so the recruiter spends the first conversation talking to candidates who already match the panel's rubric. The contrast effect that fires hardest on borderline candidates has fewer borderline reads to fire on.
The shift teams describe is consistent: the debrief stops being a memory contest and becomes a calibration session against the same evidence base. The wider bias system frame, with structured questions, evidence-anchored rubrics, and calibrated panels, runs on this same data layer. Contrast is one of the patterns it surfaces.
Contrast bias is common, subtle, and most active on the days when hiring volume is highest and the rubric is doing the least lifting. The fix is the discipline of anchoring before each interview, capturing in the room, reviewing independently before the debrief, and surfacing drift across the corpus. The next decision is fairer because the last one was anchored, captured, and audited. If the order-effect is showing up on your panels, we can show the workflow running on your hiring stack.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
Is contrast bias more common in panel interviews or one-on-one screens?
Both. Panels amplify it when round 2 has seen round 1's score before opening their own evaluation. One-on-ones amplify it when the recruiter screens six or more candidates in a single day. The structural pattern is different. Panels distort through visible anchoring, one-on-ones distort through cognitive fatigue, and the reset is the same: rubric-anchored scorecards captured before the next conversation starts.
Can structured interviews completely eliminate contrast bias?
No, and "completely eliminate" is the wrong target. Structure reduces the effect. Sequencing discipline plus captured evidence compounds the reduction across interviews. The honest version of the answer is that contrast bias is a feature of how human cognition handles sequential evaluation, so the goal is to make the rubric anchor stronger than the queue anchor, not to eliminate comparison thinking.
How does interview fatigue create contrast bias?
After about three hours of back-to-back evaluation, cognitive load shifts the brain toward comparative shortcuts. The rubric requires effortful, criterion-by-criterion assessment. Comparison to a recent candidate is faster and feels reliable in the moment. The fix is structural, not heroic: rotate interviewers across the day, cap any single panel-member's screening block at four interviews, and run an independent rubric pass before debrief.
What's the fastest way to reduce contrast bias without retraining interviewers?
Immediate scorecard capture in the room. If you do one thing this week, make every interviewer log a rubric-anchored score before the next candidate joins. Memory of the queue can't override evidence that's already written down against the criteria. The same evidence-anchored read of candidate responses compounds across the rest of the funnel, so the biggest single move is the one that fires first.



