Interview scorecards: Make faster, fairer, data-driven hiring decisions

A Director of Talent at a Series B company runs the same play every loop. She calibrates the rubric with the hiring manager, briefs the panel, runs six clean interviews.
Then she opens the scorecards the night before debrief and watches the signal leak. Three blank rows. Two soft-yeses. One rating with no rubric anchor.
The scorecard process forgot the scorecard is the channel that carries the calibrated rubric from intake into the panel's data layer. Get the channel right and every interview in the loop compounds.
This post lays out the five execution disciplines that keep that channel tight, with our Notetaker, Application Review, and Reports doing the heavy lift at the points where rubric fidelity usually breaks.
Five disciplines carry the scorecard process. The first three lock rubric fidelity inside the call. The last two move the signal to the rest of the loop, before the next interview opens cold.
Rubric and scorecard: two artifacts, one frame
Rubrics and scorecards get treated as the same thing by most teams, then they fail differently. The rubric specifies what great looks like for the role.
The scorecard puts that specification in the panel's hands during the call. One sets the standard, the other carries it.
| What the rubric is | What the scorecard is | |
|---|---|---|
| Purpose | Specification of what "strong" looks like, per competency, per role | Panel-facing structure that captures rating, evidence, and recommendation in the call |
| Owner | Hiring manager plus recruiter, signed off at calibration | Recruiter operationalizes; each interviewer fills their assigned slice |
| When it's written | Before the first sourcing pass, anchored to the success profile | Built once per role from the rubric, reused for every candidate |
| How it shows up in the loop | Reference document, often static after sign-off | Live artifact the panel fills round by round, then synthesizes at debrief |
The rubric specs. The scorecard carries. The five disciplines below are what hold the line between them when the panel is in the room and the candidate is on the call.
The five execution disciplines
Each discipline maps to a real failure mode you can name from any post-debrief review. Each has a moment in the workflow where it bites. Apply them in order; they compound.
1. Lock the rubric into the scorecard
The scorecard isn't a generic 1-5 rating sheet with a free-text comments box. It carries the rubric inline.
That means the competency labels the hiring manager signed off on, the behaviors-per-rating that anchor "strong" versus "developing," and the prompt scaffolding that tells the interviewer what to probe for.
One rubric, one scorecard. If interviewer A is rating "data modeling" against a 4-point scale and interviewer B is rating it against a 5-point scale, the panel's collected scorecards can't be combined into a thesis. Standardize at the template, not at the debrief.
Build it once per role from the rubric, then reuse it for every candidate at that level. The recruiter assigns each interviewer their slice (one or two competencies, not all of them), so the panel covers the full rubric without overlap.
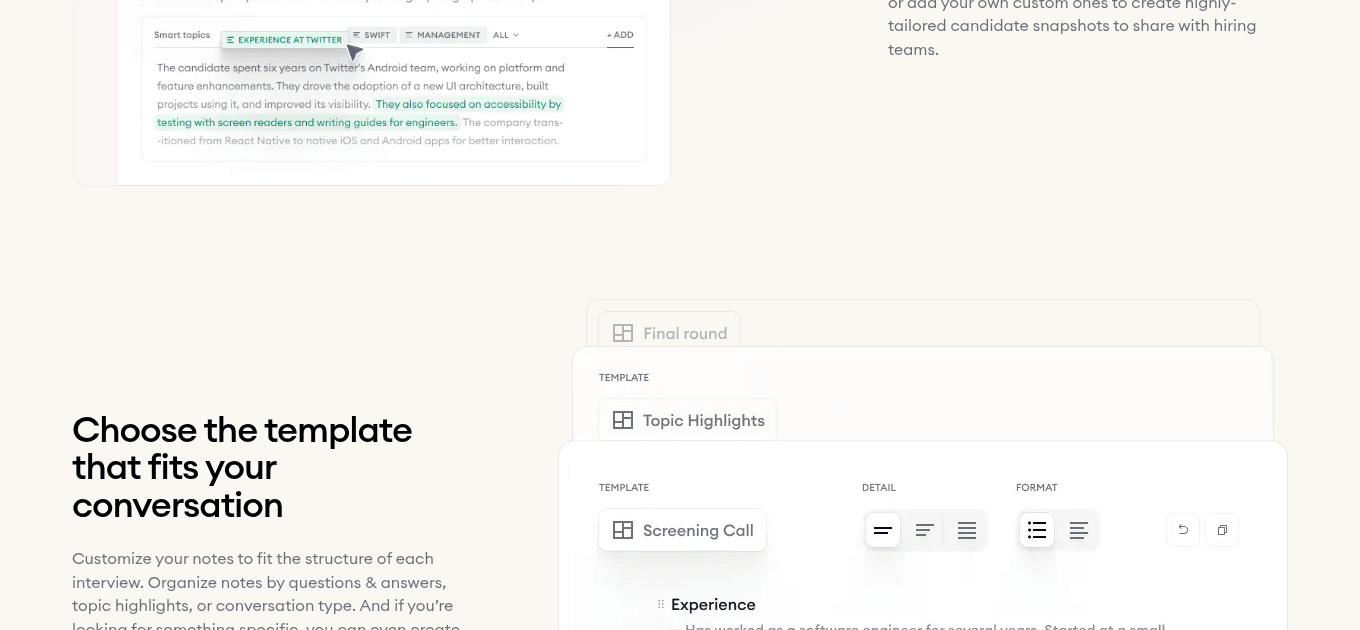
- 1Meeting type auto-detected from the calendar invite, so the right template loads without the interviewer picking from a dropdown.
- 2Template selection ties the scorecard to the role's rubric, with the competencies, behaviors, and prompts already in place.
- 3Format (screening, final round, detail) shapes what the post-call structured output looks like for the hiring manager.
2. Score in the call, not after
The longer the gap between the candidate's answer and the interviewer's rating, the more the rating drifts toward the average of every candidate they've seen this week.
Twenty minutes after the call, the voice is already fading. An hour after, the specific phrase that produced the rating is reconstructed, not remembered.
The rating locks in-call. The interviewer scores each competency at the point in the conversation where the candidate's response gives them enough signal.
The evidence sentence (one or two lines, plain prose, what the candidate said or did) gets captured at the same beat. Both land before the next question.
That's only possible if note-taking isn't competing with listening. The conventional pattern of typing while the candidate talks trades present attention for a transcript that's still incomplete.
Our Notetaker handles the capture, so the interviewer can do the work only they can do, which is reading the room.
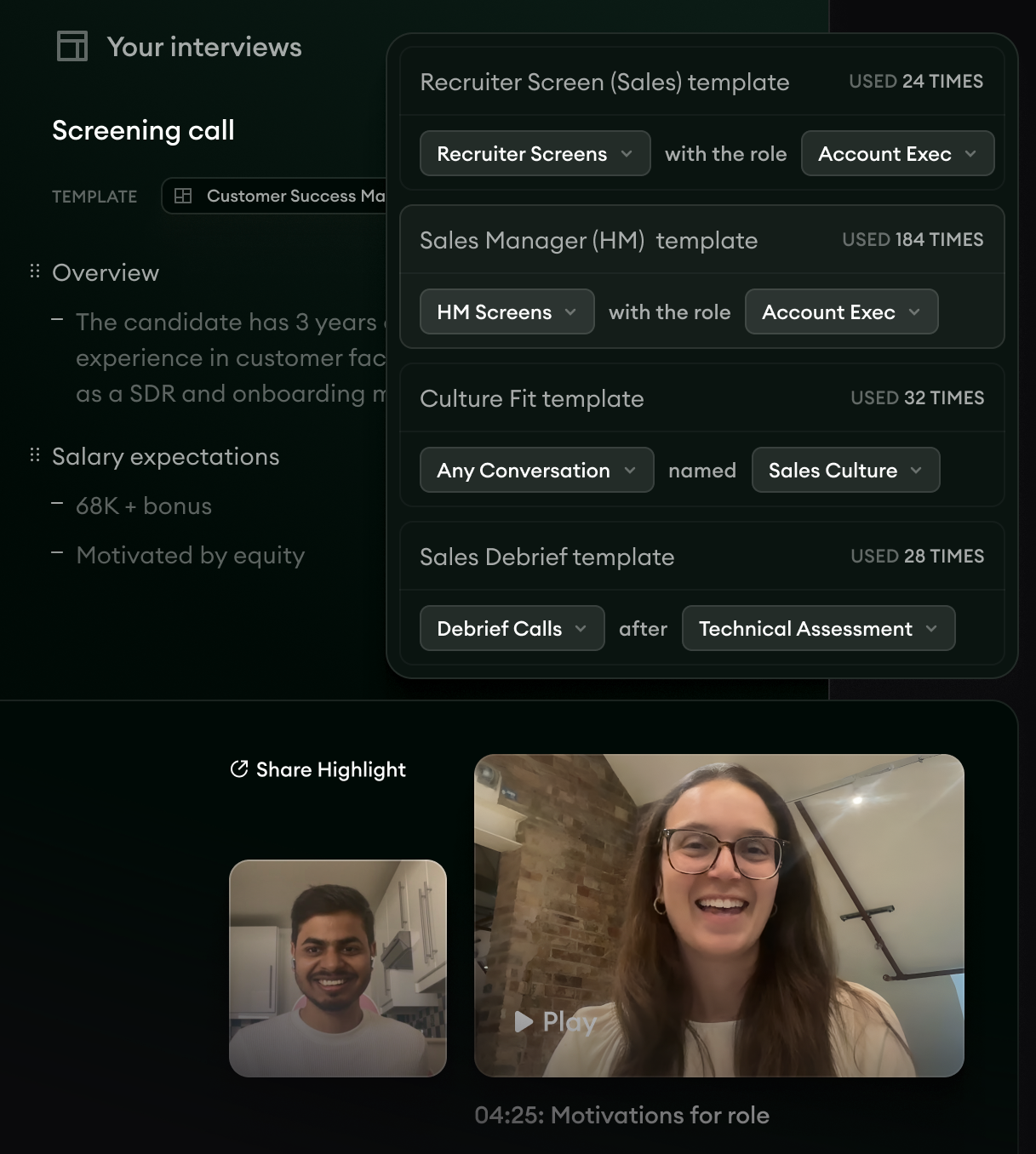
- 1The full transcript captures every word, so the interviewer doesn't have to choose between listening and typing.
- 2Structured notes route the candidate's answers into the right competency on the rubric, with the exact phrase as evidence.
- 3Video highlights make it easy to share the moment that produced the rating with the hiring manager, when memory disagrees.
3. Demand a position with evidence
The least useful scorecard in the panel's stack is the one that hedges across every competency. "Soft yes" reads as if the interviewer hasn't taken a position.
It puts the synthesis work back on the hiring manager, which is exactly the work the panel exists to share.
Position plus evidence. The interviewer's job is to land a defensible call on the slice of competencies they were assigned, with the candidate's phrase that produced it.
The position can be hedged if the slice genuinely was inconclusive ("I didn't have time to test for X, and here's the question I'd ask in the next round"). It cannot be hedged because the interviewer didn't want to commit.
Interviewers don't make the final hiring decision. They should see their mission as shedding light on a relatively small part of a person that will serve as one data point in a larger decision. Clarifying this mindset also helps to avoid situations in which an interviewer might feel confused or offended if the hiring manager ultimately makes a decision that goes against their recommendation.”
4. Bind the rating to the evidence
A rating without an evidence sentence is noise. The whole point of the structured scorecard is that the next reader can trace the rating back to what the candidate said or did.
That next reader could be the hiring manager today, or the calibration reviewer in 90 days. Without the evidence line, the rating is a feeling.
The discipline is mechanical. Every rating ships with two lines minimum: what the candidate said (the phrase, paraphrased if the recording isn't available), and what that demonstrated about the competency.
Two lines, not two paragraphs. The structured AI Notes view does most of the work by routing the candidate's actual words into the right competency slot. The interviewer adds the judgment layer.
5. Push to the ATS before the next round opens
The longest gap in most hiring loops is between when the interviewer finishes scoring and when the scorecard lands in the ATS.
A scorecard that sits in a Google Doc for three days is a scorecard the next interviewer can't see. The next round opens cold, and the panel re-asks the same questions because nobody knew they were already answered.
Before the next round opens. The scorecard, the structured notes, and the evidence sentences move into the ATS within 30 minutes of the call.
The ATS becomes the panel's working memory, not just the system of record. The hiring manager has visibility into where the candidate stands without waiting for the recruiter to forward the scorecard PDF.
What the disciplined scorecard unlocks
Disciplined scorecards aren't an end in themselves. They unlock the work the panel is supposed to be doing, which is turning four to six hours of conversation across a panel into one defensible hiring decision.
The second-order effect shows up in the hiring-manager loop. The scorecard isn't just better at capturing signal; it's coaching the hiring manager into a more consistent interview style.
Fiona Keating's recruiting team at SoSafe names this directly: structuring the questions an HM should be asking, and having those questions represented in the scorecard, is what makes the panel's signal consistent across rounds.
The rubric guides the prompts. The prompts shape the questions. The scorecard captures what came back. Three steps, one channel, no leakage.
According to Metaview's 2026 AI Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, 41% of recruiters say documentation time per interview is over 30 minutes.
Most of what gets written down never makes it back into the panel's synthesis. The 30 minutes is the symptom; the disciplined scorecard is what makes that time pay off.
How Metaview accelerates each discipline
Each of the five disciplines has a moment where the rubric and the scorecard usually drift apart. Metaview's surfaces close that gap at the moment it opens.
The rubric-anchored capture loop carries Disciplines 1 and 2. Our Notetaker loads the right template from the calendar invite, then AI Notes capture structured by the rubric the recruiter set. The "score in the call" rule stops being aspirational because the typing job is solved.
The evidence pre-fill carries Discipline 3. The structured AI Notes view routes each candidate answer into its competency with the exact phrase available as evidence. The interviewer's job becomes adding the judgment line, not reconstructing the phrase.
The ATS integration carries Disciplines 4 and 5. Application Review filters by rubric competency across the inbound funnel, and Reports surface where the panel diverged across candidates. The ATS push fires automatically on submit, inside the 30-minute window.
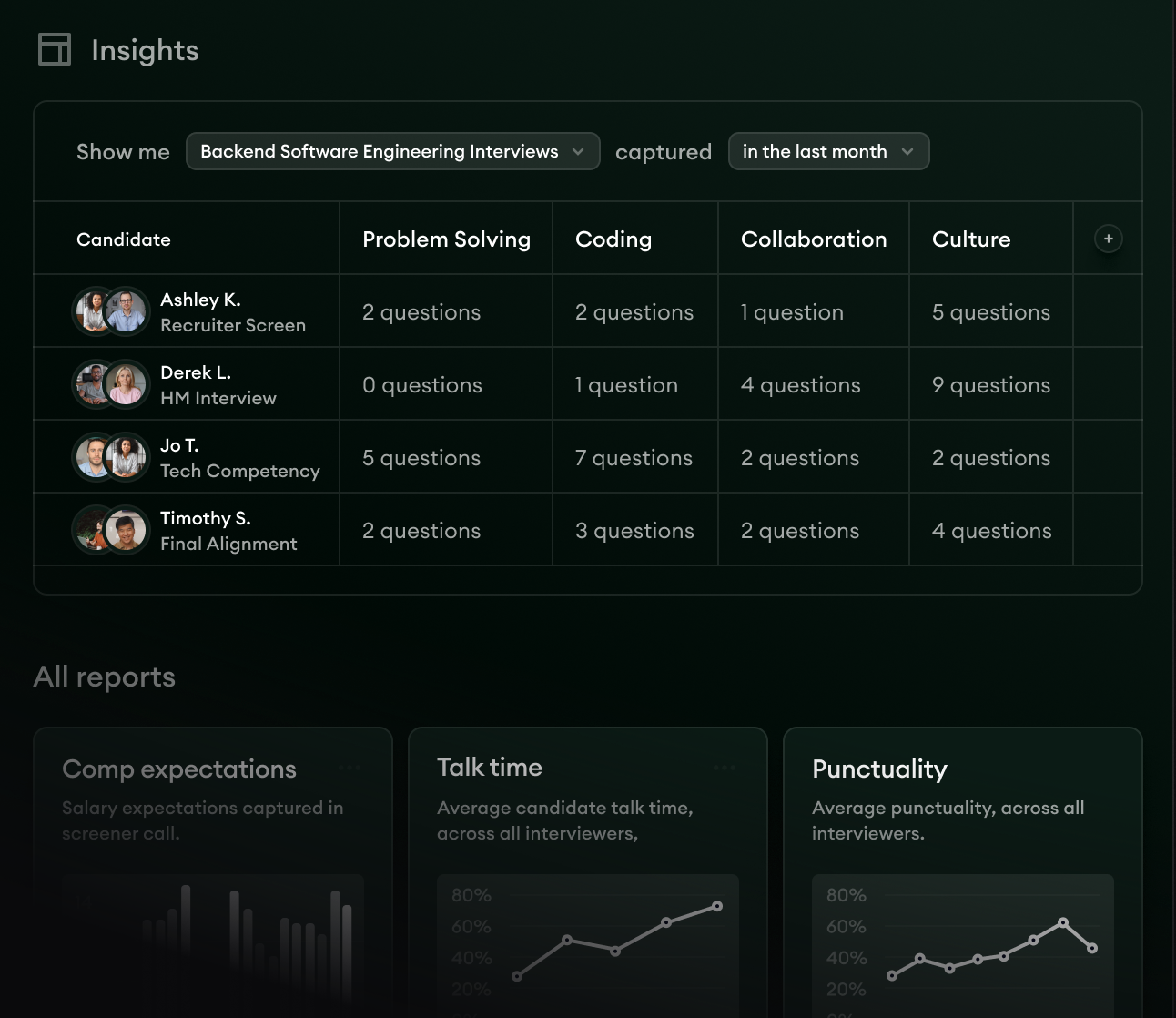
- 1Per-competency capture across every candidate at the role level, so the panel's signal is queryable, not just searchable.
- 2Cross-panel divergence surfaces where two interviewers rated the same competency differently, with the exact phrases for each.
- 3The 90-day calibration check uses this view to validate whether the interview ratings were predictive of post-hire performance.
The framing Tajbakhsh uses inside the company is that the goal of any one scorecard is to shed light on a small part of the candidate.
When the panel's scorecards land in the same structured place, they combine into a thesis. The five disciplines are what make that combination possible. The Metaview surfaces are what make the disciplines sustainable across every interview, every panel, every role.
Disciplined scorecards turn four to six interviews into one decision. They give the hiring manager a defensible position at debrief.
They give the recruiter a record they can audit at the 90-day calibration check. And they give the candidate a hiring process where the interviews built on each other.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
What's the practical difference between an interview rubric and a scorecard?
The rubric is the specification: what "strong data modeling" or "strong cross-functional collaboration" looks like for the role, signed off by the hiring manager at calibration. The scorecard is the panel-facing artifact that puts the rubric in the interviewer's hands during the call, with rating slots, evidence prompts, and the recommendation field. When you're building from scratch, write the rubric first; the scorecard is the rubric expressed as a structure the panel can fill in.
How long should it take to complete a scorecard after an interview?
Five minutes after the call ends, with Metaview's in-call AI Notes routing the candidate's responses to the right competency. The interviewer's job becomes adding the judgment line and the overall position, not reconstructing the conversation. A "complete" scorecard has a rating for every competency the interviewer was assigned, an evidence sentence of one to two lines per rating, and a clear yes-or-no recommendation with supporting context.
What if interviewers refuse to use the structured scorecard?
The pattern that breaks resistance: introduce one rubric per role, run a 30-minute panel calibration session on that rubric, and audit two scorecards per interviewer at the first debrief. By week two of using it, the panel sees the consistency benefit, with faster debriefs, cleaner hiring-manager calls, and less argument over what the candidate said. Most resistance comes from the assumption that the scorecard adds work; the in-call capture pattern shows that it removes work, just earlier in the loop.
Does Metaview integrate with the scorecard fields in our ATS?
Yes. The integration covers Greenhouse, Ashby, Lever, Workday, and Bullhorn, and the push direction maps each rubric competency to its matching ATS scorecard field. The interviewer hits submit in Metaview, the rating and the evidence sentence land in the ATS scorecard, and the panel's next interviewer can see the prior round without waiting for a forwarded PDF.
How do you measure whether scorecards are improving over time?
Three metrics, all visible in Reports. Inter-rater reliability across the panel asks whether two interviewers rating the same competency for the same candidate land within one point. Scorecard completion latency tracks the median time from interview end to ATS submit, with a target under 30 minutes. And the 90-day post-hire calibration check asks whether interview ratings were predictive of post-hire performance for hires already in seat. Those three give the recruiter a dashboard for the scorecard process itself.



